Pydantic AI observability
Trace Pydantic AI agents in PromptLayer via Logfire and OpenTelemetry. Every model call, validation, and tool invocation captured — no SDK rewrite.
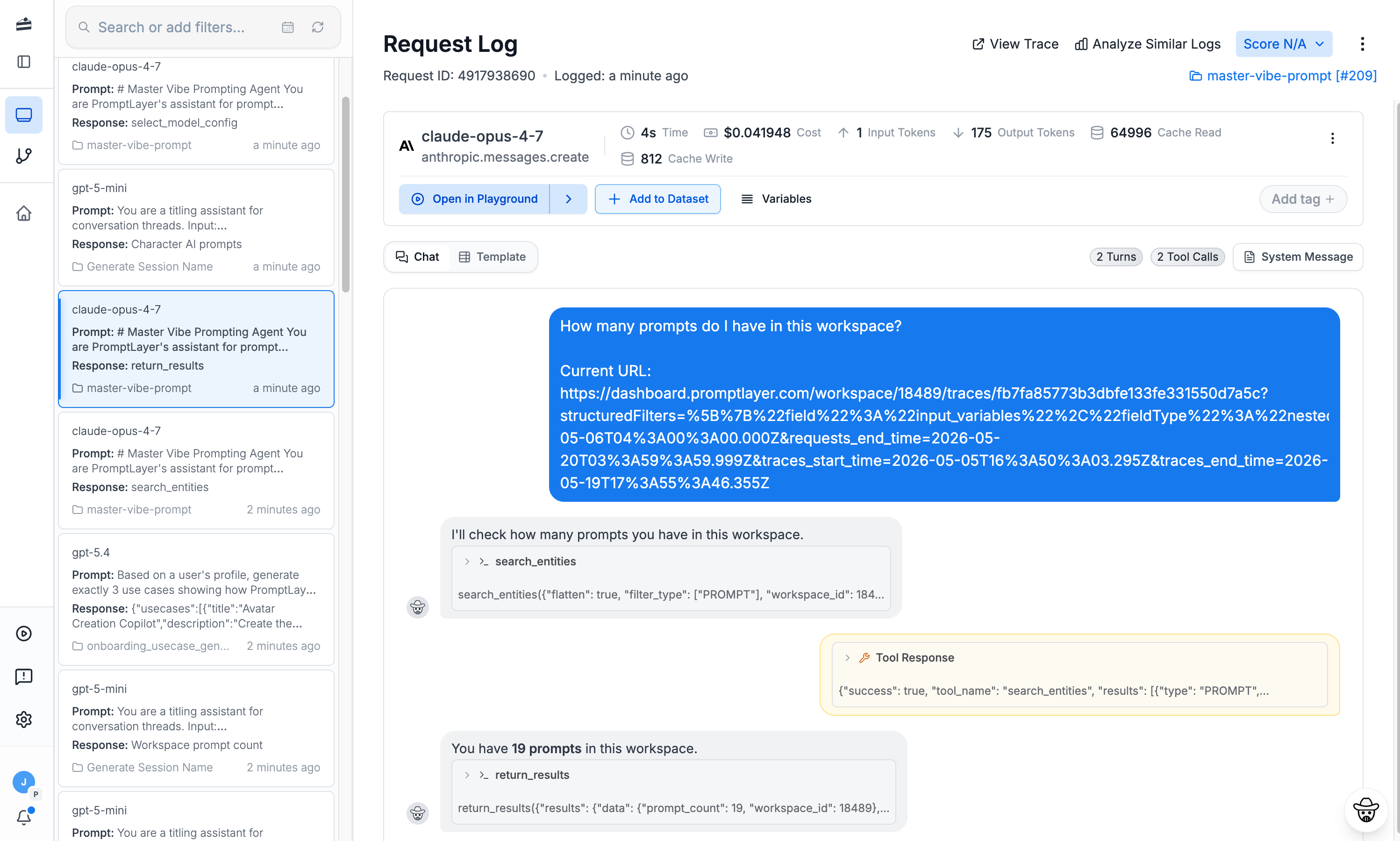
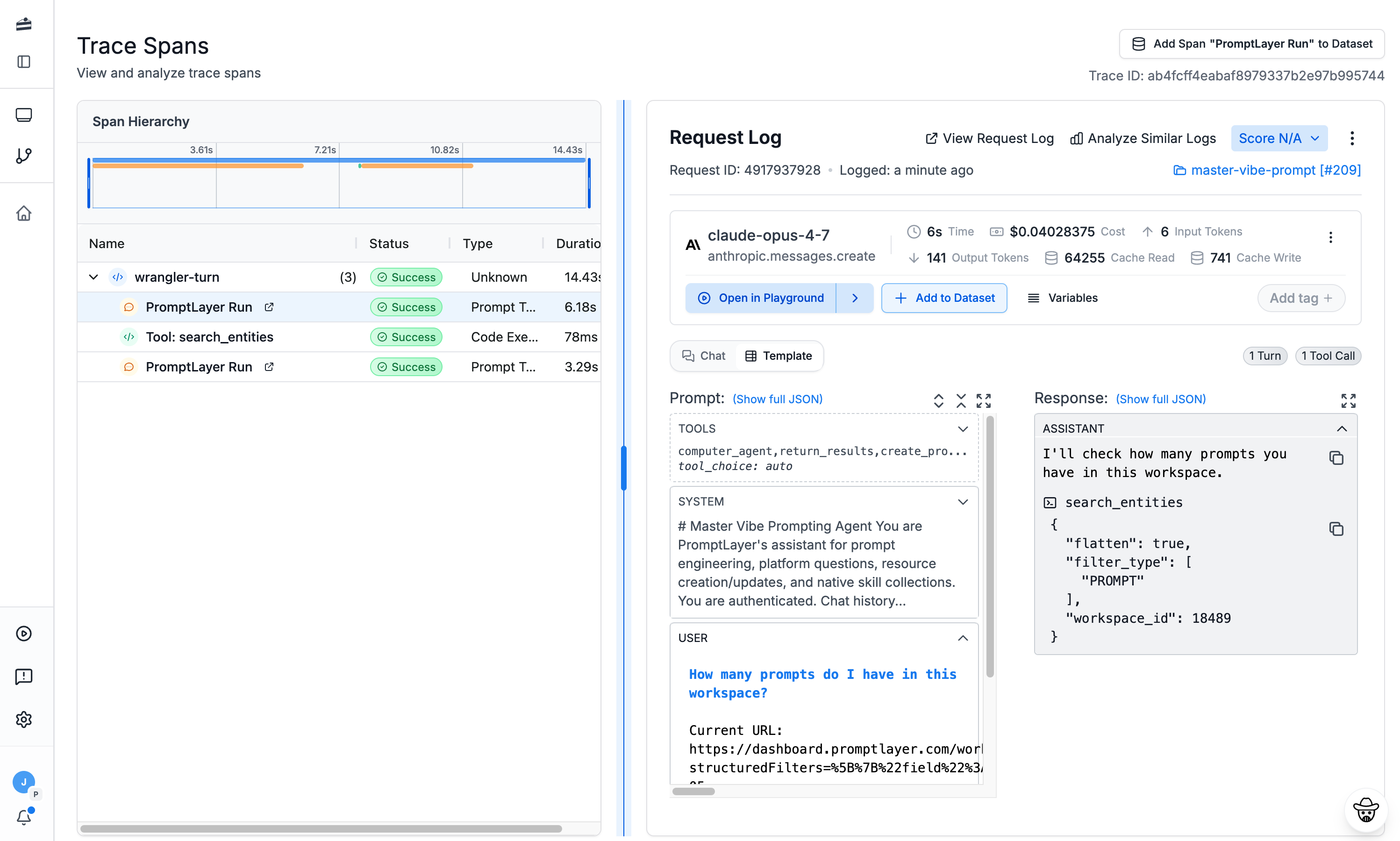
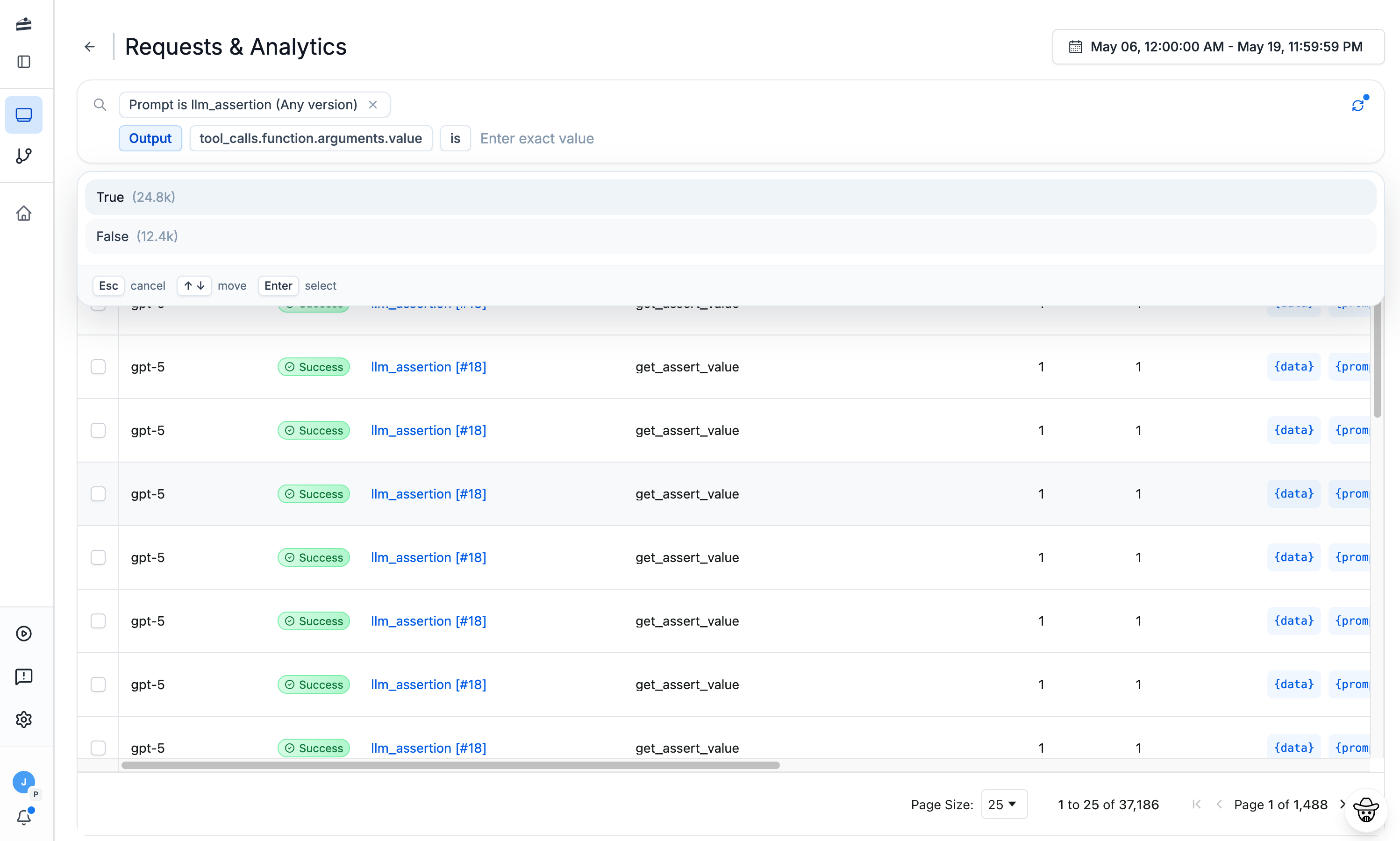
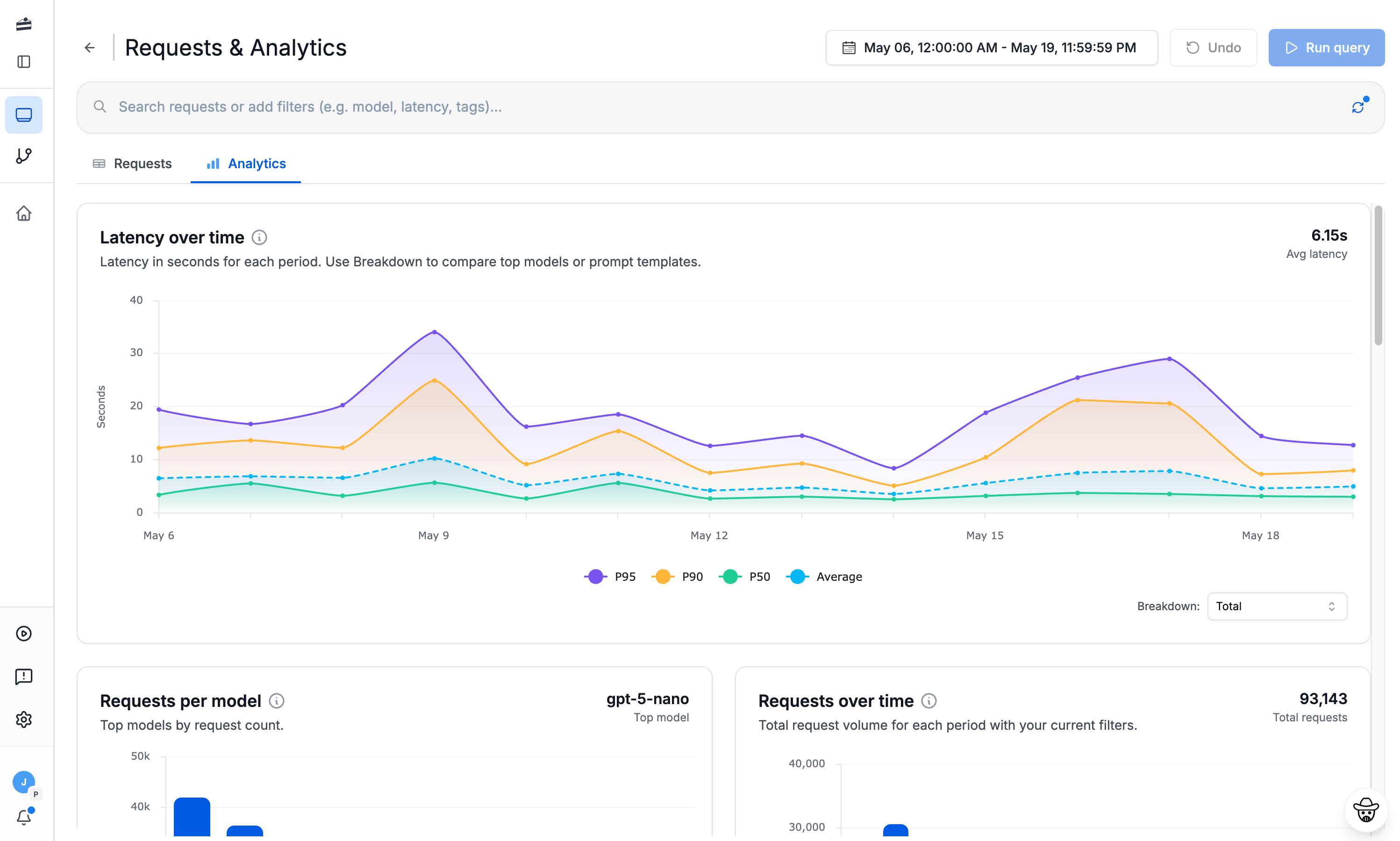
Trace every Pydantic AI run
Full span traces
See the complete execution tree of every Pydantic AI run — nested spans, tool calls, and LLM requests on one timeline.
Cost & latency analytics
Track token usage, cost, and latency for every Pydantic AI call, broken down by model, prompt, or metadata.
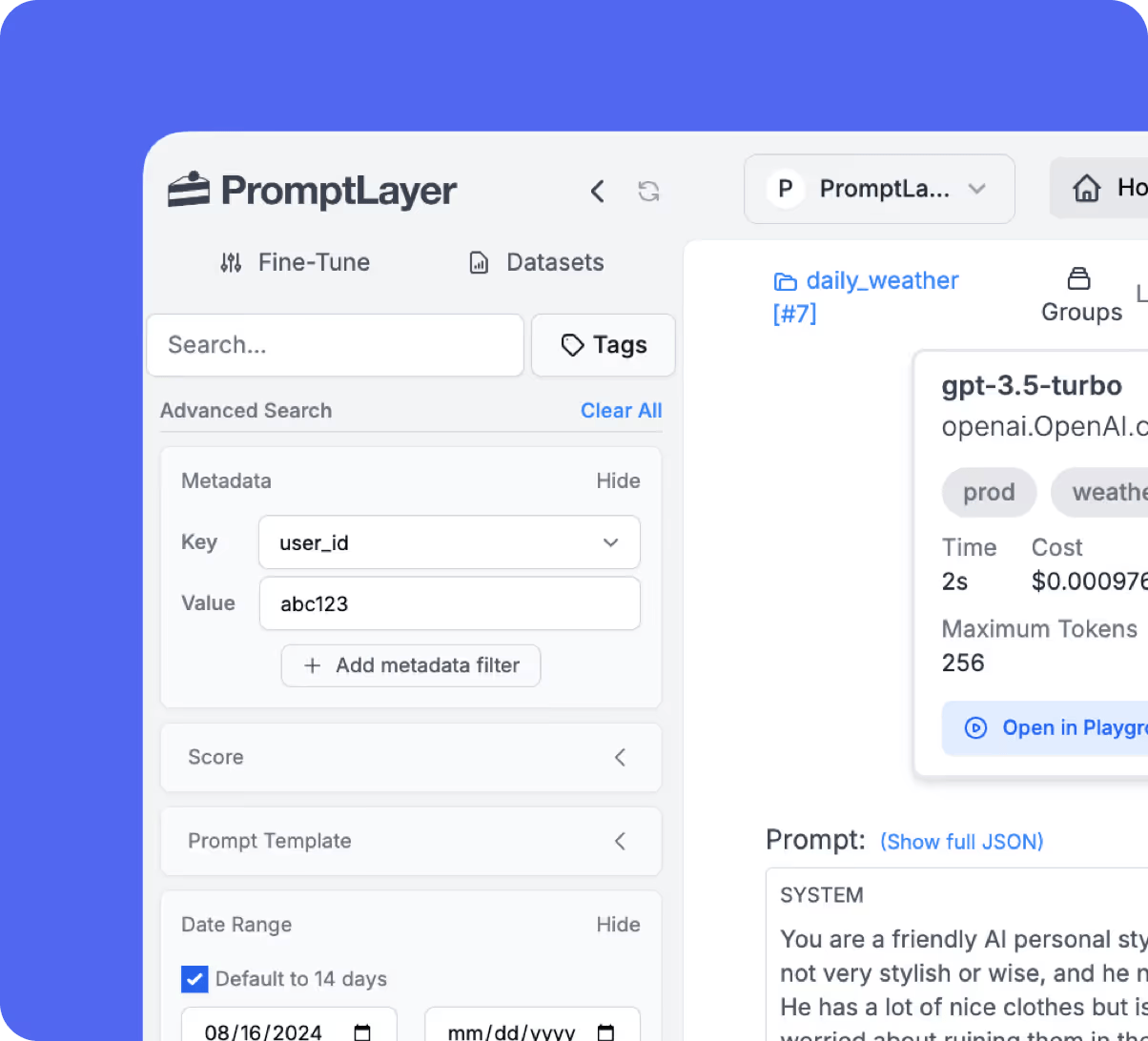
Rich metadata & search
Tag, score, and search every request. Filter production traffic by content, model, status, or custom key-value pairs.
OpenTelemetry-native
Pydantic AI streams traces straight to PromptLayer's OTLP endpoint — no proxy in your request path, no SDK rewrite.
Debug in the playground
Open any Pydantic AI trace in the Playground to reproduce, tweak, and fix the exact prompt that failed.
Turn traces into evals
Promote real Pydantic AI runs into versioned datasets and run evaluation pipelines to catch regressions.
Understand what your Pydantic AI app is doing
Pydantic AI gives you typed, structured agents. PromptLayer gives you the trace: every model call, validation, and tool invocation captured and searchable.
See the full picture
Every Pydantic AI run becomes a searchable, replayable trace — inputs, outputs, models, and timing.
Find the bottleneck
Pinpoint the slow span or expensive model call dragging down your Pydantic AI pipeline.
Catch failures fast
Surface errors, failed tool calls, and low-quality outputs before your users do.
Ship with confidence
Connect traces to evaluation pipelines so every change to your Pydantic AI app is tested.
Frequently asked questions
If you still have questions feel free to contact us at sales@promptlayer.com