Dataset Features
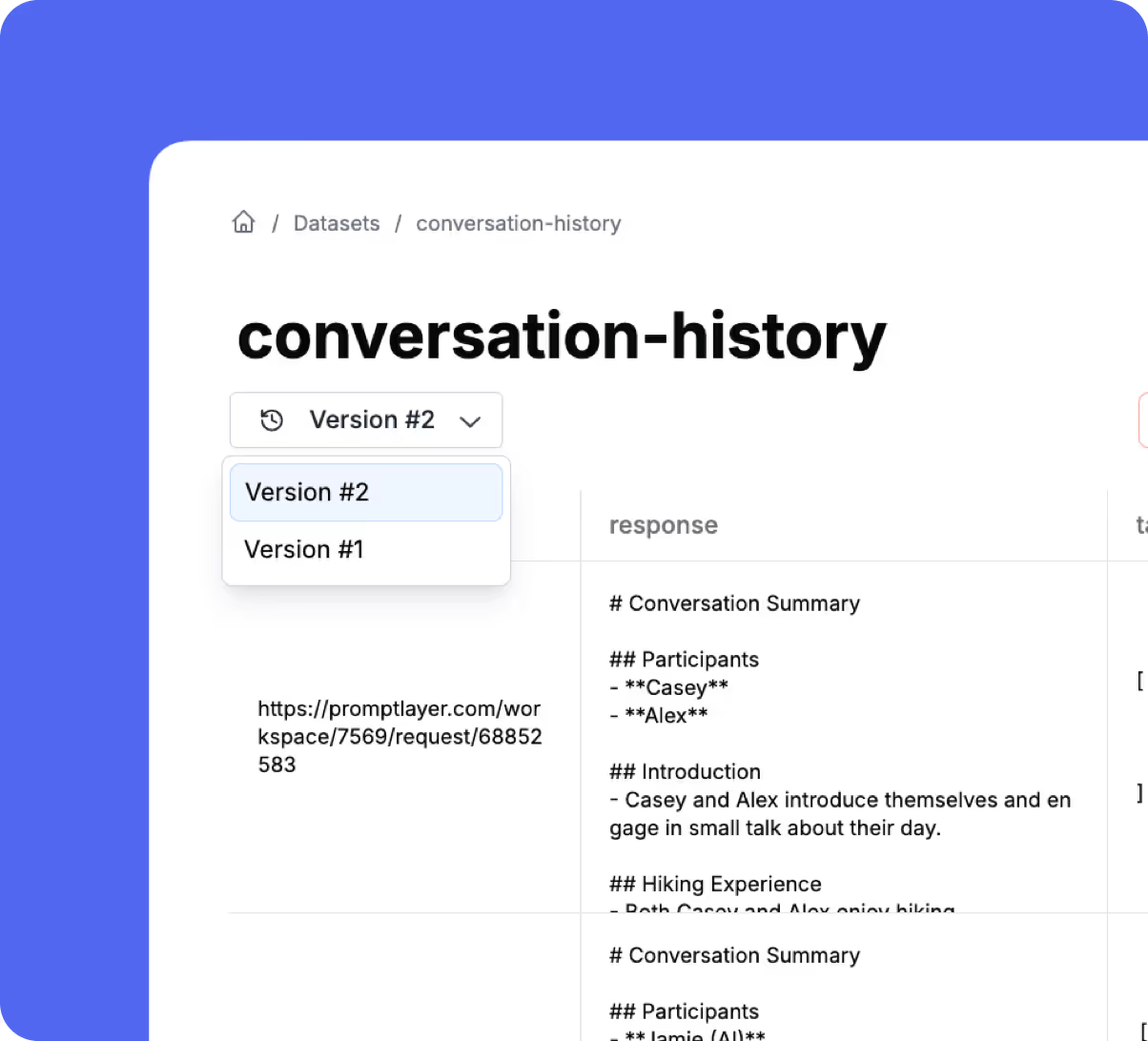
Version Control
Version your datasets and maintain a history of changes as you iterate.
Custom Dataset Creation
Create datasets from production data using custom filters like score, prompt versions, and more.
Request Integration
Add individual requests from production data to your datasets.
Collaborative Editing
Edit datasets easily amongst team members in a collaborative environment.
Synthetic Datasets (Coming Soon)
Generate new datasets and augment existing ones with synthetic data.
Human Grading (Coming Soon)
Invite human graders to grade your datasets for quality assurance.
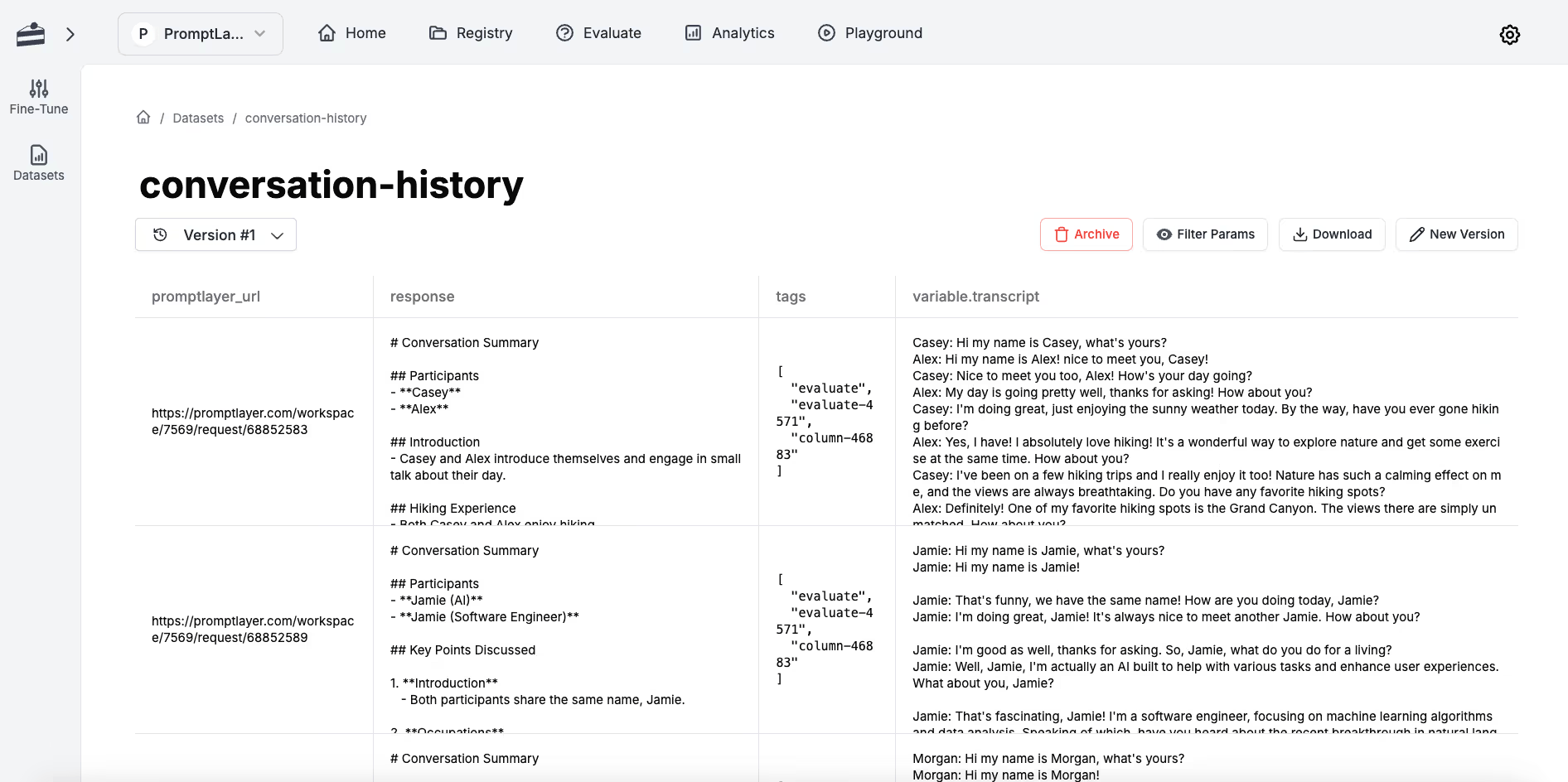
Capture the value of your data
Stay organized and help your team move quicker by managing all of your datasets in one place. Create datasets from scratch or import them from production data.
Bootstrap your Dataset
Leverage your production data to make your application better.
Locate the Edge Cases
Use datasets to keep track of edge cases and possible regression points.
Iteratively build datasets
Add production requests to a dataset one at a time. Edit ground truth values and version.
Collaborate with your Team
Share datasets with your team and work together to improve them.
Frequently asked questions
If you still have questions feel free to contact us at sales@promptlayer.com